Working with data from an adjusting amount procedure
Source:vignettes/adjusting-amounts.Rmd
adjusting-amounts.RmdThe idea of an adjusting amount procedure is to “titrate” an individual’s indifference point at a given delay. After running an experiment of this type, you may have a data table where each row corresponds to a different choice the participant made:
data("adj_amt_sim")
head(adj_amt_sim)
#> del val_del val_imm imm_chosen trial_idx
#> 1 7 800 400 FALSE 1
#> 2 7 800 600 FALSE 2
#> 3 7 800 700 FALSE 3
#> 4 7 800 750 FALSE 4
#> 5 7 800 775 FALSE 5
#> 6 30 800 400 FALSE 6In this case, you need some column to differentiate different
“blocks” of the experiment, so that a separate indifference point can be
computed for each block. In the data above, as is standard, each delay
corresponded to a different block. We can run
adj_amt_indiffs to compute the indifference points for
these blocks:
scored <- adj_amt_indiffs(adj_amt_sim)
head(scored)
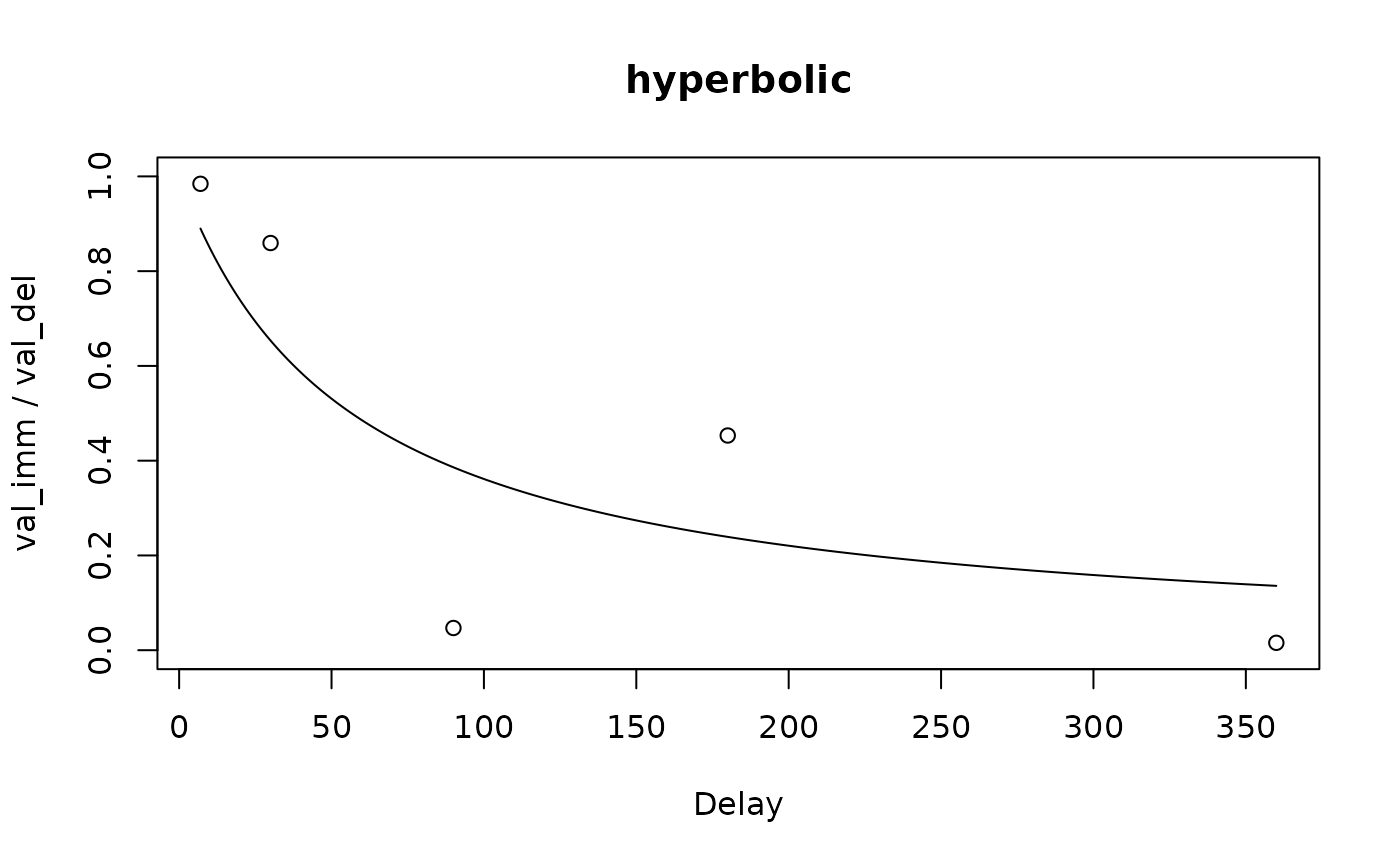
#> del indiff
#> 1 7 0.984375
#> 2 30 0.859375
#> 3 90 0.046875
#> 4 180 0.453125
#> 5 360 0.015625By default, adj_amt_indiffs assumes that there is a
column called del that differentiates between different
blocks. You can specify this manually using the block_indic
column. Similarly, adj_amt_indiffs assumes that the rows
are already in chronological order within blocks, so that the final row
corresponds to the last decision. To override this behaviour, we can use
the order_indic argument to pass the name of a column that
specifies the order in which decisions took place:
scored <- adj_amt_indiffs(adj_amt_sim, block_indic = 'del', order_indic = 'trial_idx')
head(scored)
#> del indiff
#> 1 7 0.984375
#> 2 30 0.859375
#> 3 90 0.046875
#> 4 180 0.453125
#> 5 360 0.015625With our indifference points computed, we can fit an indifference point model to the data: