Modeling binary choice data
Source:vignettes/modeling-binary-choice-data.Rmd
modeling-binary-choice-data.RmdClassic methods
For binary choice data not explicitly designed to titrate out indifference points (as in an adjusting amount procedure), there are a few widely-used traditional scoring methods to quantify discounting.
Kirby scoring
One scoring method is the one designed for the Monetary Choice Questionnaire (Kirby, 1999):
data("td_bc_single_ptpt")
mod <- kirby_score(td_bc_single_ptpt)
print(mod)
#>
#> Temporal discounting indifference point model
#>
#> Discount function: hyperbolic, with coefficients:
#>
#> k
#> 0.02176563
#>
#> ED50: 45.9439876371218
#> AUC: 0.0551987542147013Although this method computes
values according to the hyperbolic discount function, in principle it’s
possible to use other single-parameter discount functions (though this
is not an established practice and should be considered an experimental
feature of tempodisco):
mod_exp <- kirby_score(td_bc_single_ptpt, discount_function = 'exponential')
print(mod_exp)
#>
#> Temporal discounting indifference point model
#>
#> Discount function: exponential, with coefficients:
#>
#> k
#> 0.008170247
#>
#> ED50: 84.8379742026149
#> AUC: 0.0335100135964859
mod_pow <- kirby_score(td_bc_single_ptpt, discount_function = 'power')
print(mod_pow)
#>
#> Temporal discounting indifference point model
#>
#> Discount function: power, with coefficients:
#>
#> k
#> 0.3052023
#>
#> ED50: 8.69012421478859
#> AUC: 0.1173431135372
mod_ari <- kirby_score(td_bc_single_ptpt, discount_function = 'arithmetic')
print(mod_ari)
#>
#> Temporal discounting indifference point model
#>
#> Discount function: arithmetic, with coefficients:
#>
#> k
#> 1.034244
#>
#> ED50: 95.8739950116839
#> AUC: 0.0262488714558682Wileyto scoring
It is also possible to use the logistic regression method of Wileyto et al. (2004), where we can solve for the value of the hyperbolic discount function in terms of the regression coefficients:
mod <- wileyto_score(td_bc_single_ptpt)
#> Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
print(mod)
#>
#> Temporal discounting binary choice linear model
#>
#> Discount function: hyperbolic from model hyperbolic.1, with coefficients:
#>
#> k
#> 0.04372626
#>
#> Call: glm(formula = fml, family = binomial(link = "logit"), data = data_with_betas)
#>
#> Coefficients:
#> .B1 .B2
#> 0.49900 0.02182
#>
#> Degrees of Freedom: 70 Total (i.e. Null); 68 Residual
#> Null Deviance: 97.04
#> Residual Deviance: 37.47 AIC: 41.47Newer methods
Linear models
The Wileyto et al. (2004) approach turns out to be possible for other discount functions as well (Kinley, Oluwasola & Becker, 2025.):
| Name | Discount function | Linear predictor | Parameters |
|---|---|---|---|
hyperbolic.1 |
Hyperbolic (Mazur,
1987): |
||
hyperbolic.2 |
(Mazur,
1987): |
||
exponential.1 |
Exponential (Samuelson,
1937): |
||
exponential.2 |
Exponential (Samuelson,
1937): |
||
power |
Power (Harvey,
1986): |
||
arithmetic.1 |
Arithmetic (Doyle
& Chen,
2010): |
||
arithmetic.2 |
Arithmetic (Doyle
& Chen,
2010): |
||
scaled-exponential |
Scaled exponential (beta-delta; Laibson,
1997): |
, | |
nonlinear-time-hyperbolic |
Nonlinear-time hyperbolic (Rachlin,
2006): |
, | |
nonlinear-time-exponential |
Nonlinear-time exponential (Ebert & Prelec,
2007): |
, |
Where is the logit function, or the quantile function of a standard logistic distribution, and is the quantile function of a standard Gumbel distribution.
We can test all of these and select the best according to the Bayesian Information Criterion as follows:
mod <- td_bclm(td_bc_single_ptpt, model = 'all')
#> Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
#> Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
#> Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
#> Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
print(mod)
#>
#> Temporal discounting binary choice linear model
#>
#> Discount function: arithmetic from model arithmetic.2, with coefficients:
#>
#> k
#> 1.287432
#>
#> Call: glm(formula = fml, family = binomial(link = "logit"), data = data_with_betas)
#>
#> Coefficients:
#> .B1 .B2
#> 3.9532 0.9988
#>
#> Degrees of Freedom: 70 Total (i.e. Null); 68 Residual
#> Null Deviance: 97.04
#> Residual Deviance: 12.81 AIC: 16.81Nonlinear models
To explore a wider range of discount functions, we can fit a
nonlinear model by calling td_bcnm. The full list of
built-in discount functions is as follows:
| Name | Functional form | Notes |
|---|---|---|
exponential (Samuelson, 1937) |
||
hyperbolic (Mazur, 1987) |
||
scaled-exponential (Laibson, 1997) |
Also known as quasi-hyperbolic or beta-delta and written as | |
nonlinear-time-exponential (Ebert & Prelec,
2007) |
Also known as constant sensitivity | |
inverse-q-exponential (Green & Myerson,
2004) |
Also known as generalized hyperbolic (Loewenstin & Prelec), hyperboloid (Green & Myerson, 2004), or q-exponential (Han & Takahashi, 2012) | |
nonlinear-time-hyperbolic (Rachlin, 2006) |
Also known as power-function (Rachlin, 2006) | |
dual-systems-exponential (Ven den Bos & McClure,
2013) |
||
additive-utility (Killeen, 2009) |
is the value of the delayed reward. for . | |
power (Harvey, 1986, eq.
2) |
In equation 2 of the reference, the discount function is described as , but time begins at . | |
arithmetic (Doyle & Chen,
2010) |
is the value of the delayed reward. for . | |
fixed-cost (Benhabib, Bisin, &
Schotter, 2010) |
is the value of the delayed reward. for . | |
absolute-stationarity (Blavatskyy, 2024,
eq. 3) |
The original paper uses rather than . However, a scale factor appears necessary to account for different time units. | |
relative-stationarity (Blavatskyy, 2024,
eq. 7) |
The original paper uses rather than . However, a scale factor appears necessary to account for different time units. | |
constant (Franck et al., 2015) |
Null model; participants can be excluded if this model provides the best fit (Franck et al., 2015) | |
nonlinear-time-power |
Experimental extension of the power discount function
along the lines of the nonlinear-time-hyperbolic and
nonlinear-time-exponential functions. |
|
nonlinear-time-arithmetic |
Experimental extension of the arithmetic discount
function along the lines of the nonlinear-time-hyperbolic
and nonlinear-time-exponential functions. |
|
scaled-hyperbolic |
Experimental extension of the hyperbolic discount
function along the lines of the scaled-exponential
function. |
mod <- td_bcnm(td_bc_single_ptpt, discount_function = 'all')
print(mod)
#>
#> Temporal discounting binary choice model
#>
#> Discount function: arithmetic, with coefficients:
#>
#> k gamma
#> 1.05682221 0.08007441
#>
#> Config:
#> noise_dist: logis
#> gamma_scale: linear
#> transform: identity
#>
#> ED50: 93.8257558942613
#> AUC: 0.0256880960367851
#> BIC: 25.5896625868426Choice rules
Several additional arguments can be used to customize the model. For example, we can use different choice rules—the “logistic” choice rule is the default, but the “probit” and “power” choice rules are also available (see this tutorial for more details):
Error rates
It is also possible to fit an error rate that describes the probability of the participant making a response error (see Vincent, 2015). I.e.: where is the probability of choosing the immediate reward, is the link function, and is the linear predictor.
data("td_bc_study")
# Select the second participant
second_ptpt_id <- unique(td_bc_study$id)[2]
df <- subset(td_bc_study, id == second_ptpt_id)
mod <- td_bcnm(df, discount_function = 'exponential', fit_err_rate = T)
plot(mod, type = 'endpoints', verbose = F)
lines(c(0, 1), c(0, 0), lty = 2)
lines(c(0, 1), c(1, 1), lty = 2)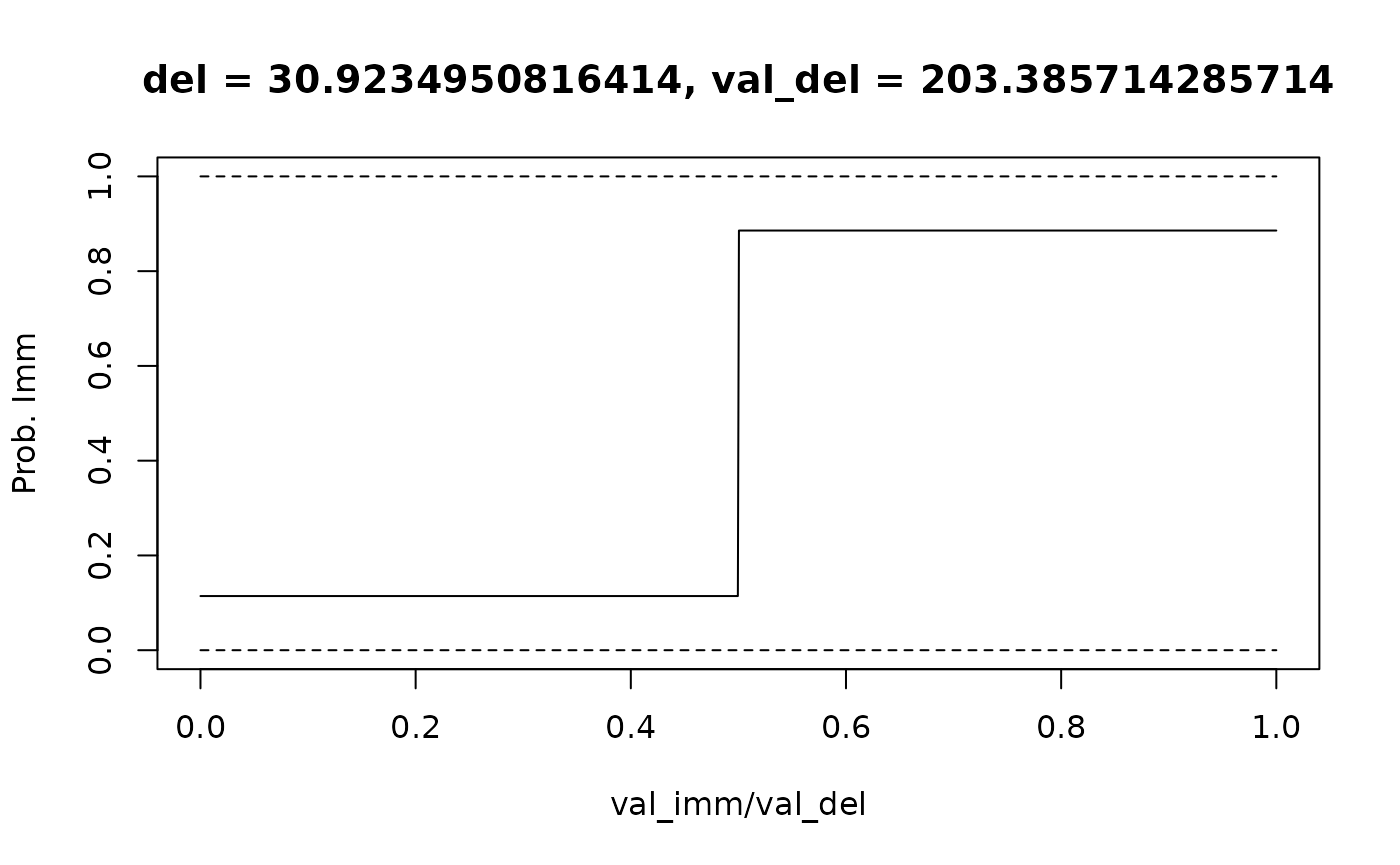
We can see that the probability of choosing the immediate reward doesn’t approach 0 or 1 but instead approaches a value of .
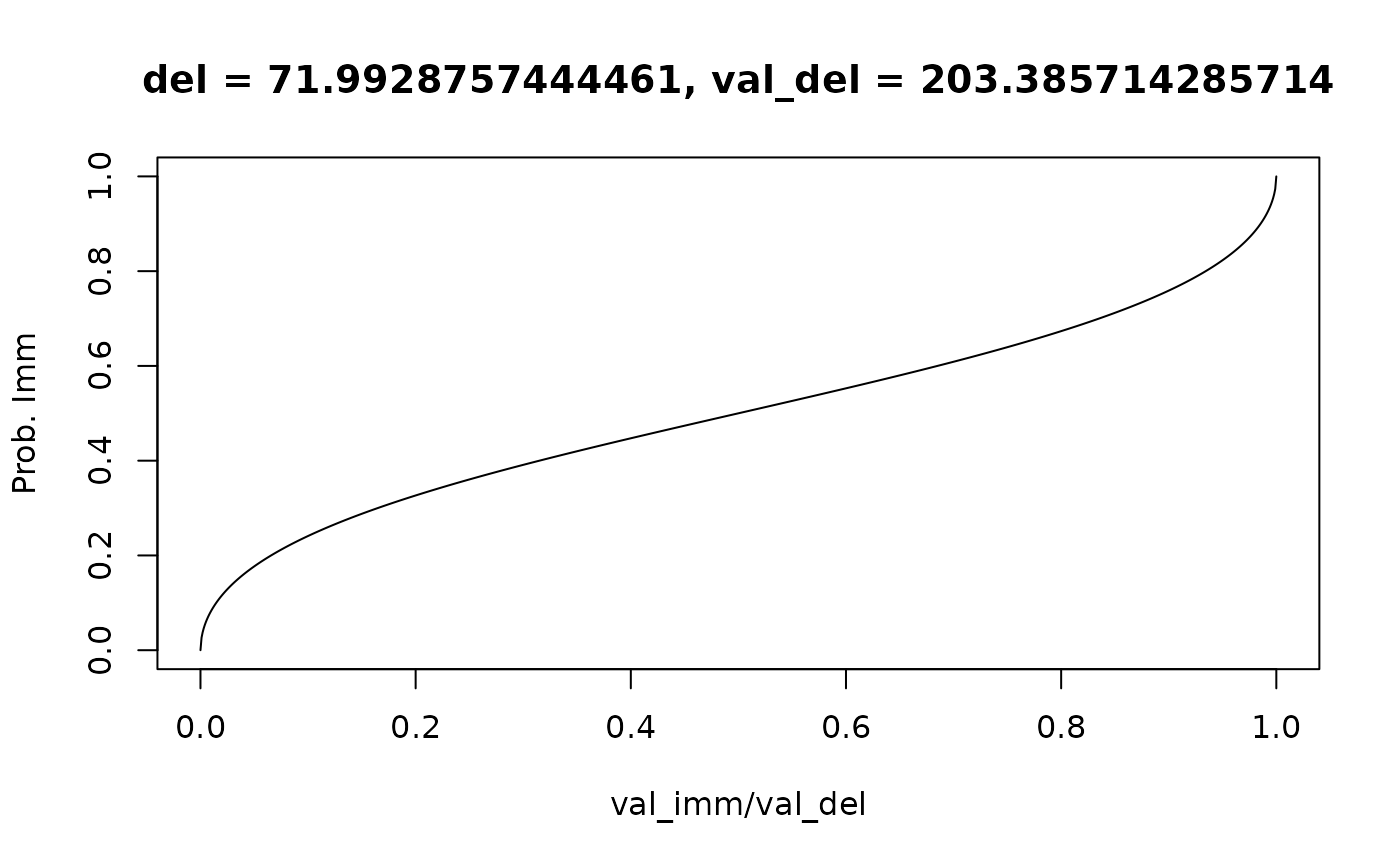
Fixed endpoints
Alternatively, we might expect that participants should never choose
an immediate reward worth 0 and should never choose a delayed reward
worth the same face amount as an immediate reward (Kinley, Oluwasola &
Becker, 2025; see here
for more details). We can control this by setting
fixed_ends = T, which “fixes” the endpoints of the
psychometric curve, where val_imm = 0 and
val_imm = val_del, at 0 and 1, respectively:
mod <- td_bcnm(df, discount_function = 'exponential', fixed_ends = T)
plot(mod, type = 'endpoints', verbose = F, del = 50, val_del = 200)